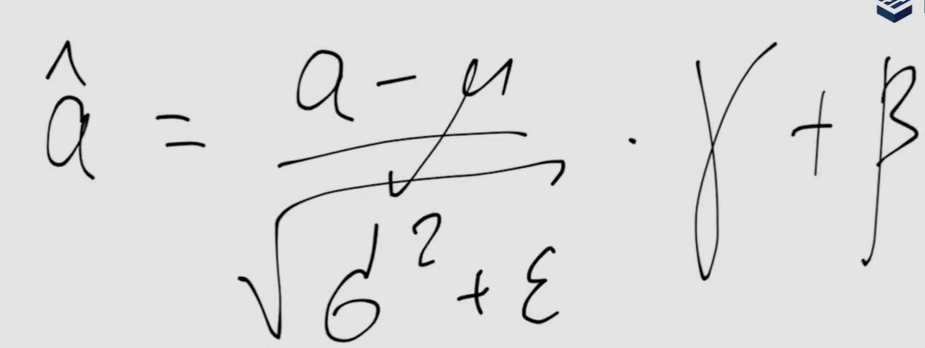during the backpropagation the last layer get updated first and prior layers later. By the time all layers are updated, the weights of the last layer are not optimal, because the distribution of weights for the previous layers already changed.
The assumption was that this effect makes training neural network more difficult (along with vanishing gradients and exploding gradients, training degradation) and the batch normalization will improve that. that appeared not to be actually true but batch normalization was very useful anyway for different reasons.
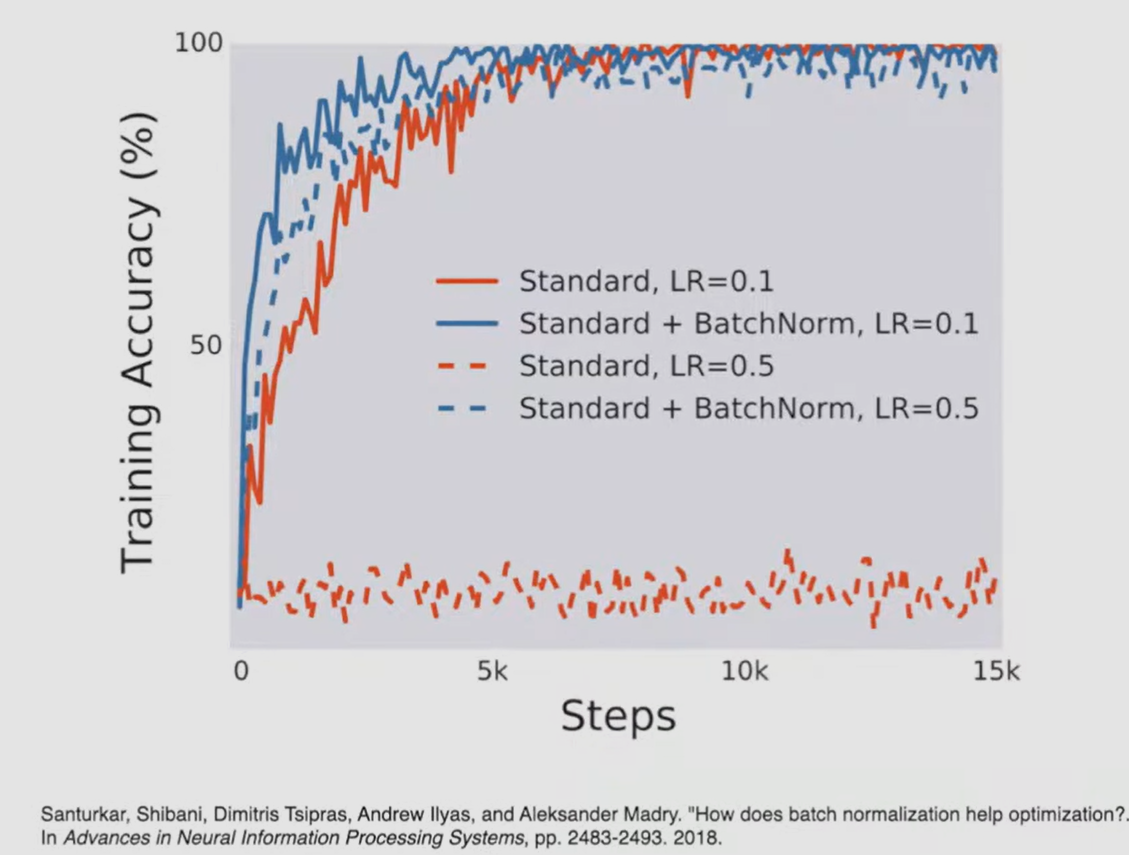
after further study, it appears batch normalization doesn’t help internal covariate shift, which in turn doesn't really disturb model training. But another useful property appeared: thanks to batch normalization surface of the cost function we optimize becomes smoother.
batch normalization was a disruptive method, still used in running-in-prod networks, but ==most modern papers about network design do not use it (not suitable for transformers because inputs aren’t independent==
Advantages
allows training deeper neural network due to cost function smoothing
Disadvantages
bound to mini-batches, requires that samples inside those are independent (for fair parameters estimation). It is mostly ok for classification tasks, but
sometimes we input sequences
acts differently for training and inference step (need to be switched off prior to inference)
Two trainable parameters, gamma and beta, are added to the neural network, which means the network can neglect the operation, if it suits it.
mu and sigma are estimated from the mini-batch that is supplied to the network, using the whole dataset wouldn’t be efficient, but that also means that with small mini-batches of four or eight it doesn’t work well. For estimating mu and gamma in practice is used exponential moving average - parameter values N steps ago is taken with a coefficient<1 in power N