parameter efficient fine-tuning
scroll ↓ to Resources
Contents
- Note
- [[#Note#Adapters|Adapters]]
- [[#Note#LoRA|LoRA]]
- [[#Note#Prompt Tuning|Prompt Tuning]]
- [[#Note#Activation scalers|Activation scalers]]
- [[#Note#bias-only|bias-only]]
- [[#Note#Sparse weight deltas|Sparse weight deltas]]
- Resources
Note
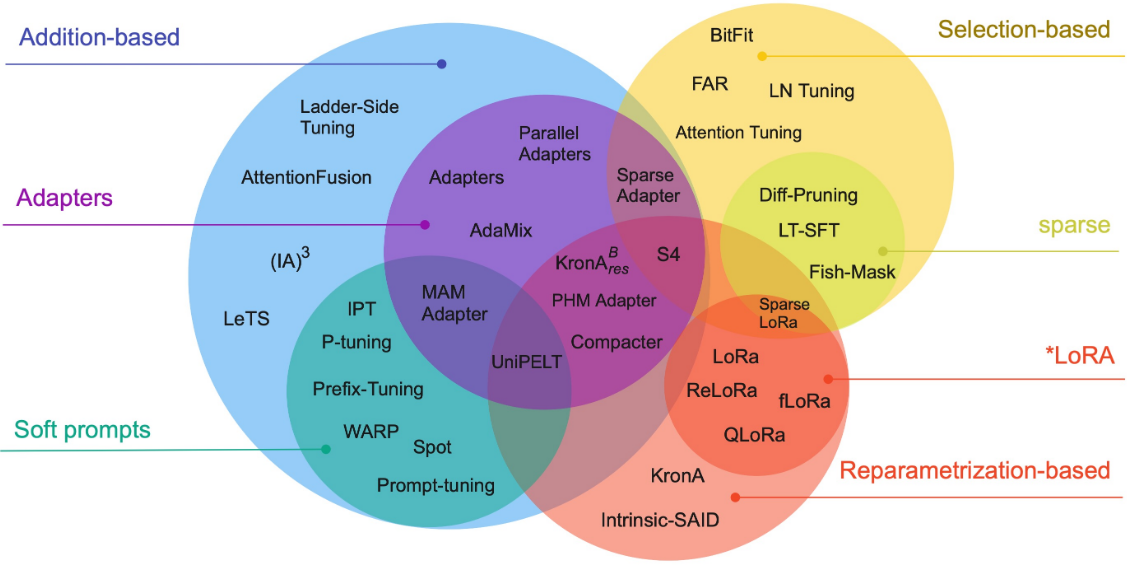
Methods
Adapters
- Add a small trainable module inside each transformer layer. These are separate from the layers, unlike in LoRA

from Parameter-Efficient Transfer Learning for NLP
LoRA
Transclude of LoRA#note
Prompt Tuning
- Learn extra embeddings, virtual tokens, instead of inserting new subnetworks.
Activation scalers
- Add three scaling vectors per layer
bias-only
- Fine-tune existing bias terms. No new parameters are inserted.
Sparse weight deltas
- Learn a sparse mask of weight differences on top of the frozen weights.
Resources
Transclude of base---related.base
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"