Advanced RAG techniques
scroll ↓ to Resources
Contents
- Advanced improvements to RAG
- [[#Advanced improvements to RAG#Chunking|Chunking]]
- [[#Advanced improvements to RAG#Fine-tuning|Fine-tuning]]
- [[#Advanced improvements to RAG#Reranker|Reranker]]
- [[#Advanced improvements to RAG#Other|Other]]
- [[#Advanced improvements to RAG#Not RAG-specific|Not RAG-specific]]
- [[#Advanced improvements to RAG#Other|Other]]
- Resources
Advanced improvements to RAG
Note
RAG intertwines with the general topic of model evaluation, and adjacent to such things as synthetic data generation for RAG evaluation and Challenges with RAG
Chunking
Chunking strategy
Note
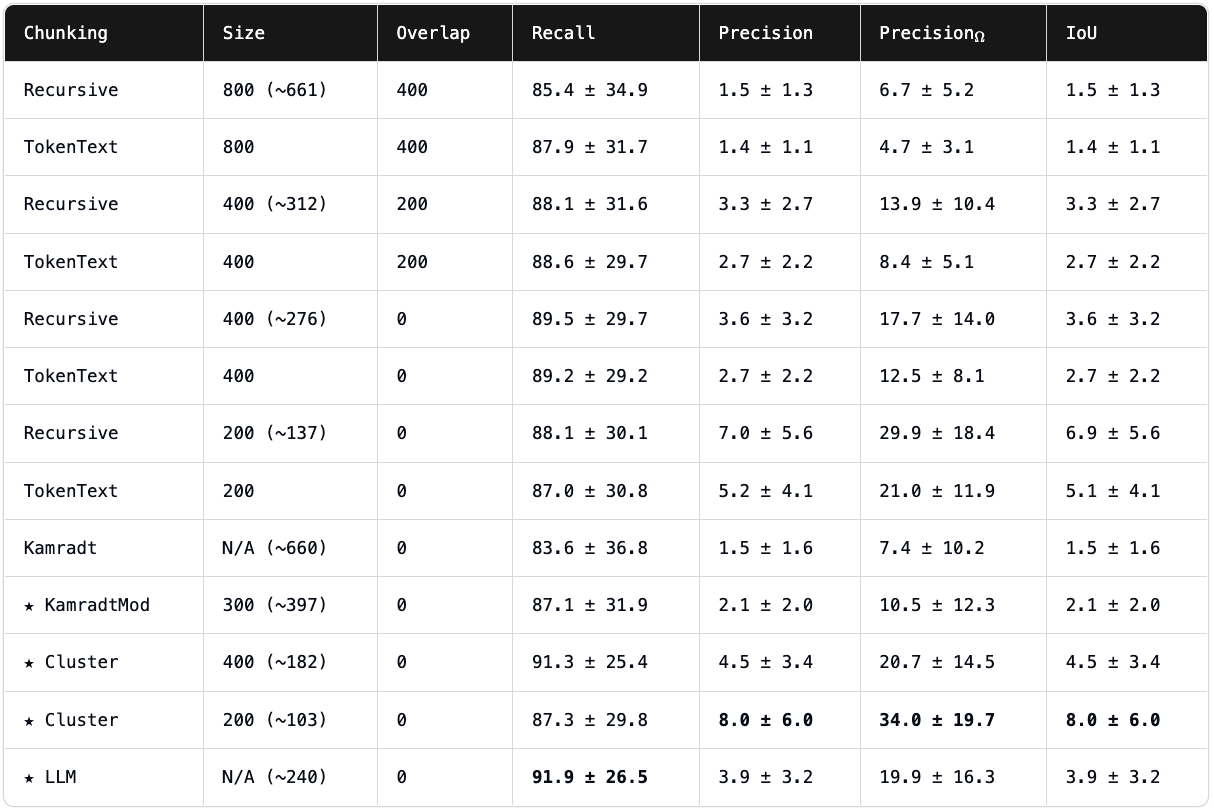
- ==chunking strategy== can have a huge impact on RAG performance. ^c77646
- small chunks ⇒ limited context ⇒ incomplete answers
- large chunks ⇒ noise in data ⇒ poor recall
- general, but not-universal advice: use larger chunks for fixed-output queries (e.g. extracting a specific answer\number) and smaller chunks for expanding-output queries (e.g. summarize, list all…).
- By symbols, sentences, semantic meaning, using dedicated model or an LLM call
- semantic chunking by detecting where the change of topic has happened
- Consider inference latency, number of tokens embedding models were trained on
- Overlapping or not?
- Use small chunks on embedding stage and large size during the inference, by appending adjacent chunks before feeding to LLM
- page-size chunks, because we answer the question “on which page can I find this?”
- sub-chanks with links to a parent-chunk with larger context
- hierarchical chunking gradually zooms into relevant context and improves efficiency of clarifying questions within a multi-turn conversation
- multiple levels based on document metadata, sections, pages, paragraphs and sentences
- Each chunk retains information about its metadata, hierarchical level, parent-child relationship, extracts confidence scores, etc.
- Shuffling context chunks will create randomness in outputs, which is comparable to increasing diversity of the downstream output (as an alternative to hyperparameter tuning using softmax temperature) - e.g. previously purchased items are provided in random order to make recommendation engine output more creative ^447647
- shuffle the order of retrieved sources to prevent position bias
- unless sources are sorted by relevance (the model assumes that the 1st chunk is the most relevant)
- newer models with large context windows are less prone to the Lost in the Middle effect and have improved recall across the whole context window
Link to originalChunking rankings from https://research.trychroma.com/evaluating-chunking
Fine-tuning
- Not RAG-specific, but off-the-shelf embedding models can be fine-tuned like any other model. It requires sufficient data, but can prove very useful the more specific is the task at hand.
- handcraft hard positive and hard negative examples
- fine-tuning to make models output citations\ref to avoid hallucination in critical domains ^95a6c6
- create source\chunk ids and use them as tags in metadata, possibly include first\last 3 words. Then fine-tuning the model
- validate the existence of citations, possibly validate semantic relevance of the content
- Start with small batches, measure performance, and increase data volume until you reach your desired accuracy level.
Better search
- In addition, to dense embedding models, historically, there are also sparse representation methods. These can and should be used in addition to vector search, resulting in hybrid search ^f44082
- Using hybrid search (at least full-text + vector search) is standard to RAG, but it requires combining several scores into one ^6fd281
- use weighted average
- take several top-results from each search module
- use Reciprocal Rank Fusion, mean average precision, NDCG, etc.
- example: Faiss and kNN use our embedding and BM25TF-IDF use their own representation
- metadata filtering reduces the search space, hence, improves retrieval and reduces computational burden, prevents index staleness
- Dates. freshness\timestamps, source authority (for health datasets), business-relevant tags
- categories: use named entity recognition models: GliNER
- if there is no metadata, one can ask LLM to generate it,
- less beneficial if your index is small or query types are limited
- create search tools specialized for your use-cases, rather than search for data types. The question is not whether I am searching for semantic or structured data?, but which tool would be the best to use for this specific search? ^c819e0
- Generic document search that searches everything, Contact search for finding people, Request for Information search that takes specific RFI codes.
- Evaluate the tool selection capability separately
- Make the model write a plan of all the tools it might want to use for a given query. Possibly present the plan for users approval, creates valuable training data based on acceptance rates.
- The naming of tools significantly impacts how models use them. Naming it grep or else can affect the efficiency.
- separate indices for document categories
- extract specific data structures for each type
- see here
- formatting ^9d73c5
- Does Prompt Formatting Have Any Impact on LLM Performance?
- check which format (markdown, json, xml) works best for your application. there are also discussions about token-efficiency
- spaces between tokens in markdown tables (like ”| data |” instead of “|data|”) affects how the model processes the information.
- The Impact of Document Formats on Embedding Performance and RAG Effectiveness in Tax Law Application
- Does Prompt Formatting Have Any Impact on LLM Performance?
- Synonyms and taxonomic similarity
- Generating more user queries with synonyms may not be effective, because synonyms do not fit the context
- If there is a taxonomy list, like for instance in ecommerce, one can create a prompt to classify a user query to one of those taxonomy entries, e.g.
furniture>Baby furniture>Crib&Toddler bed accessoriesand then search among hyponyms (children, more specific concepts), hypernyms (parents, more general groups) or siblings (similar to the selected category).
Reranker
- reranker
- see Re-ranking
- minimize using of manual boosting (e.g. boost recent content or specific keywords)
Other
- See also Inference Scaling for Long-Context Retrieval Augmented Generation
- One can generate summary of documents (or questions to each chunk\document) and embed that info too
- query expansion and enhancement to make queries look more alike to documents in the database
- Another LLM-call-module can be added to rewrite and expand the initial user query by adding synonyms, rephrasing, complementing with initial LLM output (without RAG context), etc.
- if costs are not an issue, multiple copies of the same query can be processed for higher confidence (e.g. intent recognition)
- implement intent recognition and reroute simple queries to simple handlers, no need for a full RAG pipeline, if something can be answered with an SQL or metadata filtering
- multi-agent vs single-agent systems
- communication overhead if agents are NOT read-only, need to align who modifies what
- if all read-only, for instance, in search of personality info - one may search professional sources, one about personal life, another smth else
- benefit of multi-agents - token efficiency, Especially if there are more tokens than one agent can consume in the context
- The performance just increases with the amount of tokens each sub-agent is able to consume. If you have 10 sub-agents, you can use more tokens, and your research quality is better
Extra
- AutoML tool for RAG - auto-configuring your RAG
- Contextual Retrieval \ Anthropic
- Query Classification / Routing - save resources by pre-defining when the query doesn’t need external context and can be answered directly or using chat history.
- Multi-modal RAG, in case your queries need access to images, tables, video, etc. Then you need a multi-modal embedding model too.
- Self-RAG, Iterative RAG
- Hierarchical Index Retrieval - first search for a relevant book, then chapter, etc.
- Graph-RAG
- Chain-of-Note
- Contextual Document Embeddings
Resources
- GitHub - NirDiamant/RAG_Techniques: This repository showcases various advanced techniques for Retrieval-Augmented Generation (RAG) systems
- Yet another RAG system - implementation details and lessons learned : r/LocalLLaMA
- AI Engineering - Chip Huyen
- ^bb3c46
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"