Embeddings aim to obtain a low dimensional representation of the original data in a continuous vector space, while preserving most of the essential information
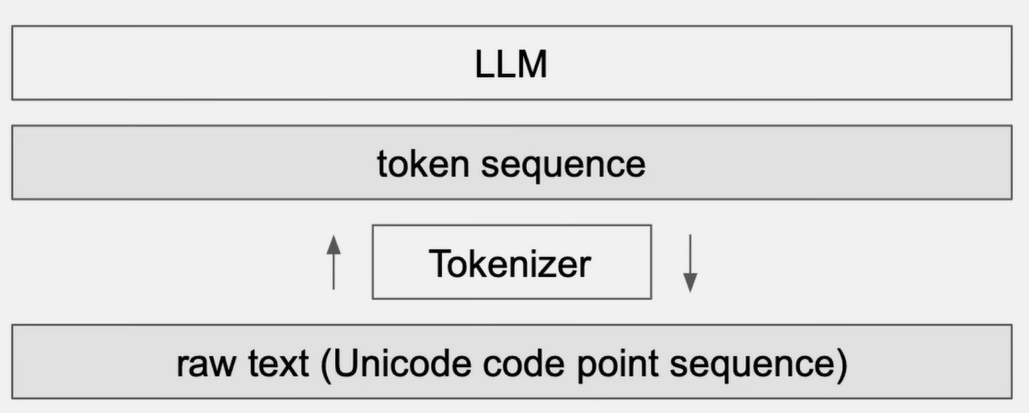
Tokenization is a substep of the embedding process, distinct, but connected
Tokenizer is an object separate from an LLM model, a preprocessing stage that requires an (independent) multi-language training set
more training data in a particular language fed into tokenizer results in denser sequences, which is beneficial for the attention mechanism with limited context length
After training a tokenizer once, it is used for encoding and decoding
Feeding raw bytes of each character (UTF-8) into LLM would make the process tokenization-free, but it would stretch the attention over much longer number of tokens, and make it prohibitively expensive, that’s why we resort to byte pair encoding
Embeddings generally take more space than the original data, which creates a large storage footprint of vector databases
The vocabulary shouldn’t be too large. Indeed, with each token we need to store its embedding vector and too many embedding vectors will clog our GPU memory. Further, it’s also not so good if the ratio of the LLM parameters concentrated in your embedding layer is too high. Ideally, a vocabulary should contain a prescribed number of tokens (like 10K or 50K).
with word-level tokenization, the main problem is that you can’t get an exhaustive list of all the words in the universe. Thus, during the inference stage, your LLM will always encounter new slang, new typos, and new languages which it hasn’t seen during training.
The items in the vocabulary should be meaningful, otherwise an LLM will struggle to make sense of them.
charactrer-level tokenization is not good
Common issues due to tokenization
due to tokenization LLM has issues with many simple tasks (spelling, simple string processing) or has problems when encountering strings like < |endofstring| >, etc. many of the issues were patched in advanced models or using tools and agents in combination with LLM
spelling words, spelling tasks like reversing strings: some tokens denote multiple quite long character sequences, so too much is cramped into one token
asking the model to split a string into a list of characters first and then answer your question helps
LLM are worse at handling non-English language, not only because the model itself has seen less data, but also because the tokenizer was trained on less data from other languages, so its compression is worse
GPT4 has seen major improvements in Python coding vs GPT2 partially due to the way their new tokenizer handled repeated spaces and indentation
handling of special tokens by chance encountered in the input: < |endofstring| >
trailing whitespace issue: the model is really confused, because it has never or rarely seen whitespace without anything after that, same is true for incomplete special tokens like .DefaultCellSty instead of the .DefaultCellStyle.
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"