how to evaluate LLM chatbots
scroll ↓ to Resources
Contents
- Note
- [[#Note#Human Feedback|Human Feedback]]
- [[#Note#Compare to the ground truth|Compare to the ground truth]]
- [[#Note#Split into subblocks|Split into subblocks]]
- [[#Note#Compare with other LLMs|Compare with other LLMs]]
- Resources
Note
Big part of GenAI projects being deployed these days - are chatbots and knowledge extraction in different flavors. Such projects’ PoC development times reduced drastically compared with classical ML projects, but the caveat now shifted to their comprehensive and unequivocal evaluation.
Below is a conceptual guide on how a mainstream LLM product can be tested.
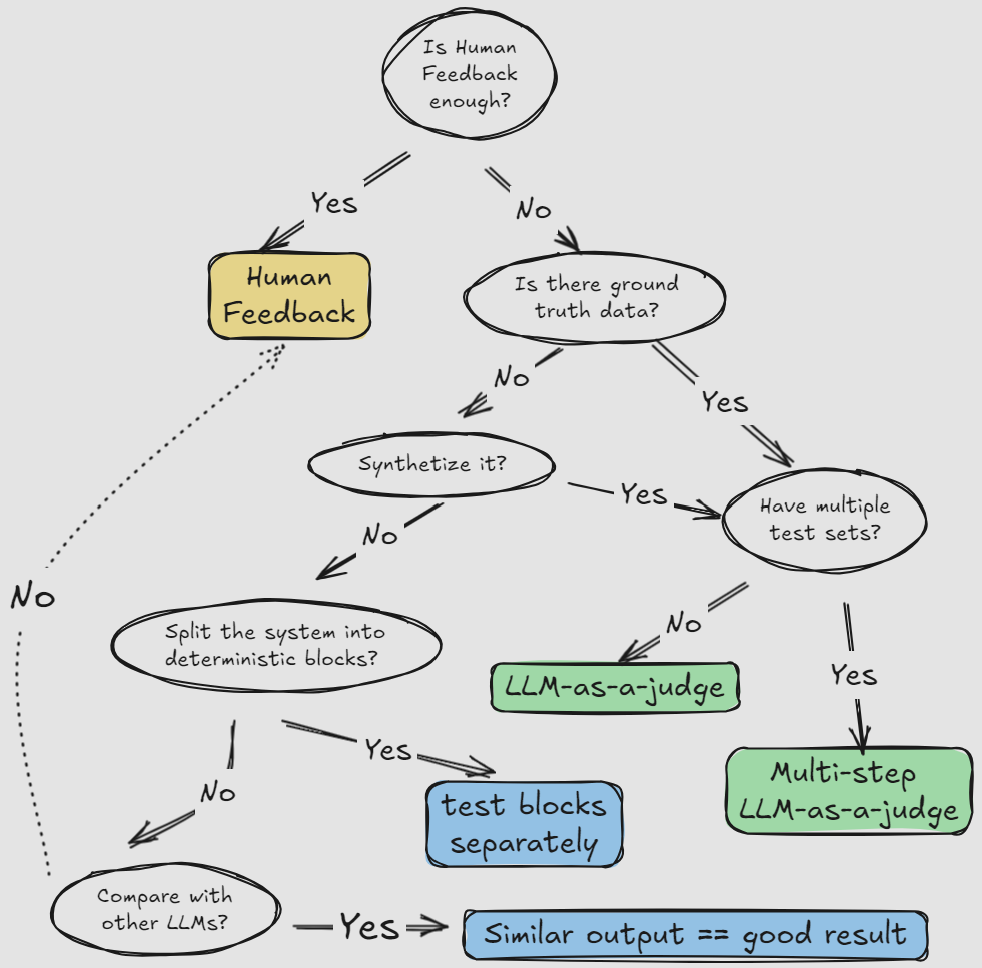
Human Feedback
First what probably comes to mind is human feedback. It is highly subjective, inconsistent proxy metric of your system’s performance in production. Despite all this it is an absolute must-have, because it is cheap and fast indicator that something is wrong and needs to be investigated further. Moreover, it is often the ultimate business metric that the project aims to increase - satisfaction scores, ticket deflection rate, ticket-to-human-agent-rate, etc. These are all metrics to fetch from real-time usage.
Compare to the ground truth
Another approach is the comparison against the ground truth. Just like with normal supervised learning. The ground truth is either LLM-generated or handcrafted dataset with question-answer pairs representative of end-users requests. Then use the LLM-as-a-judge method for comparing the chatbot output with the expected answer.
Advice on the process itself - if there is enough data, split it into several hard-to-crack test sets of 20-50 queries each. As the chatbot system development proceeds, you will want to test it at different stages to also monitor progress in: 1) scores achieved and 2) development iteration duration. The product is improving if: 1) The scores improve. 2) Time it took the developers to improve the scores, at least, stays constant. Better if this goes down, but definitely not up. If either of these conditions breaks - go to square one and reconsider your design decisions.
Best practice of the LLM-as-a-judge method itself is to have a detailed evaluation prompt(s) and ask LLM to return scores from 1 to 5 across several metrics (e.g. factual correctness, formatting, conciseness, style, completeness, coherence and others). These scores are then weight-averaged to get the final number. This number can be compared across various models or, for instance, fine-tuned vs RAG-enhanced implementation. This logic can be implemented ad-hoc or through evaluation frameworks like Ragas.
Split into subblocks
Although, LLM-as-a-judge seems straightforward and can work well for some, sometimes it can lead to a lot of frustration and inconclusive results, because essentially we try to evaluate one complex system (chatbot) with another complex system (LLM) using unstructured, undeterministic protocol (raw text).
Alternative way is to make the task more testable in the sense of traditional software systems. Split the system into one block that outputs automatically verifiable intermediate results and another block, which unwraps those results into “creative” stream of tokens.
Take for example an enterprise case of “chatting with corporate documents”. Make the first block return reference info such as exact document, subsection and page in a structured format (e.g. json). Test sets of type “Query : Relevant sections” (Table-driven tests) is easier to interpret than the prior one with “Query : Answer”. One can sure use Jacard index, precision and recall.
Then the “creative block” is tested independently, but now the prompt is supplemented either with correct references or relevant context directly. Of course, this does not guarantee 0 chance of hallucinations after the blocks are integrated, but, at least, it can help isolate the source of problems.
Compare with other LLMs
If the system is a monolith, and there is no ground truth data (can’t be generated either), another LLM still can be used, but not as a judge, but rather a peer. If our system’s output is close enough to one or more other outputs suggested by peers - this counts as evaluation success. If selected peers are models of different sizes, we can estimate in relative terms how good is our model on this particular task.
Resources
Publish links
- how to evaluate LLM chatbots. how to say if your undetermenistic… | by Andrejs | Jan, 2025 | Medium
- how to evaluate LLM chatbots - Andrejs’ Substack
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"