chunking strategy
scroll ↓ to Resources
Note
- This whitepaper Finding the Best Chunking Strategy for Accurate AI Responses | NVIDIA Technical Blog claims that Performance curves aren’t always linear, Query characteristics influence optimal chunk size and Inconsistent patterns even within similar document types, so there is no one size fits all.
- ==chunking strategy== can have a huge impact on RAG performance. ^c77646
- small chunks ⇒ limited context ⇒ incomplete answers
- large chunks ⇒ noise in data ⇒ poor recall
- general, but not-universal advice: use larger chunks for fixed-output queries (e.g. extracting a specific answer\number) and smaller chunks for expanding-output queries (e.g. summarize, list all…).
- By symbols, sentences, semantic meaning, using dedicated model or an LLM call
- semantic chunking by detecting where the change of topic has happened
- Consider inference latency, number of tokens embedding models were trained on
- Overlapping or not?
- Use small chunks on embedding stage and large size during the inference, by appending adjacent chunks before feeding to LLM
- page-size chunks, because we answer the question “on which page can I find this?”
- sub-chanks with links to a parent-chunk with larger context
- parent-child chunking, when search is done on smaller chunks but the context gets filled with, for instance, full page data
- hierarchical chunking gradually zooms into relevant context and improves efficiency of clarifying questions within a multi-turn conversation
- multiple levels based on document metadata, sections, pages, paragraphs and sentences
- Each chunk retains information about its metadata, hierarchical level, parent-child relationship, extracts confidence scores, etc.
- Shuffling context chunks will create randomness in outputs, which is comparable to increasing diversity of the downstream output (as an alternative to hyperparameter tuning using softmax temperature) - e.g. previously purchased items are provided in random order to make recommendation engine output more creative ^447647
- shuffle the order of retrieved sources to prevent position bias
- unless sources are sorted by relevance (the model assumes that the 1st chunk is the most relevant)
- newer models with large context windows are less prone to the Lost in the Middle effect and have improved recall across the whole context window
- shuffle the order of retrieved sources to prevent position bias
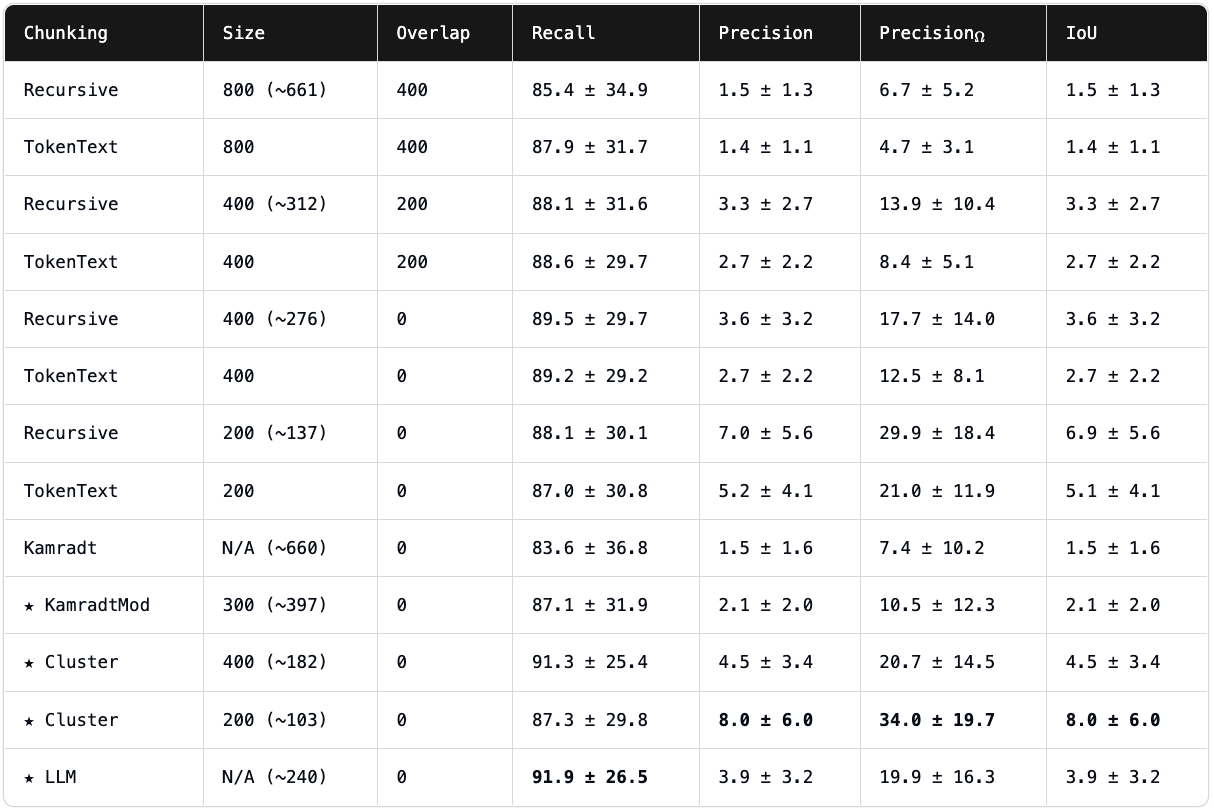
Chunking rankings from https://research.trychroma.com/evaluating-chunking
Resources
- r/Rag - Best chunking strategy for RAG on annual/financial reports?
- Text splitters | 🦜️🔗 LangChain
- Finding the Best Chunking Strategy for Accurate AI Responses | NVIDIA Technical Blog
Transclude of base---related.base
Links to this File
table file.inlinks, filter(file.outlinks, (x) => !contains(string(x), ".jpg") AND !contains(string(x), ".pdf") AND !contains(string(x), ".png")) as "Outlinks" from [[]] and !outgoing([[]]) AND -"Changelog"