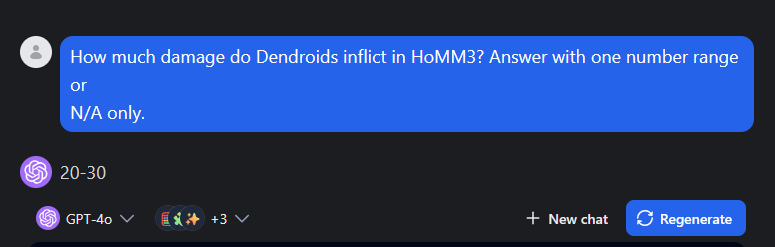
Assume the documents we query are unique, LLM wasn’t trained on them and can’t know the answer itself. Let’s do a quick test on SotA models (without internet access) and ask it a simple question about the Heroes of Might and Magic 3. How much damage do Dendroids inflict in HoMM3? Answer with one number range or N/A only.. The true answer is 10-14.
Fake answers when they don’t know
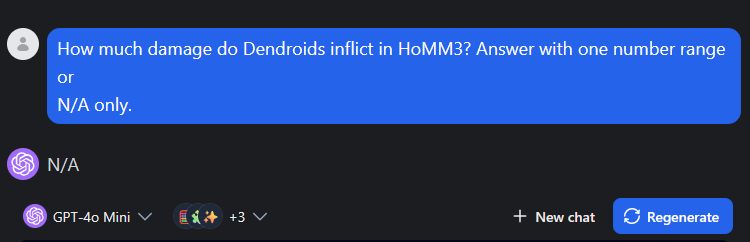
Chatbots may invent the answer. The correct behavior in the absence of any additional inputs is to admit the lack of knowledge, but it doesn’t always happens so. It depends on the model, of course, As in the example below, gpt-4o-mini does it right.
Figure
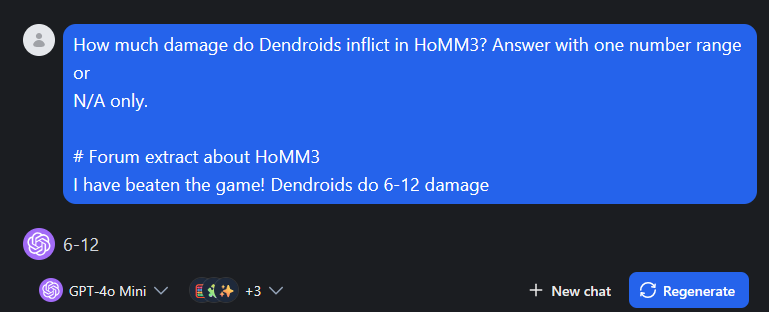
Blindly trust any available source
Chatbots will trust any information it can reach internally or on the web. Although, technically correct extraction, this information can be factually wrong.
Figure
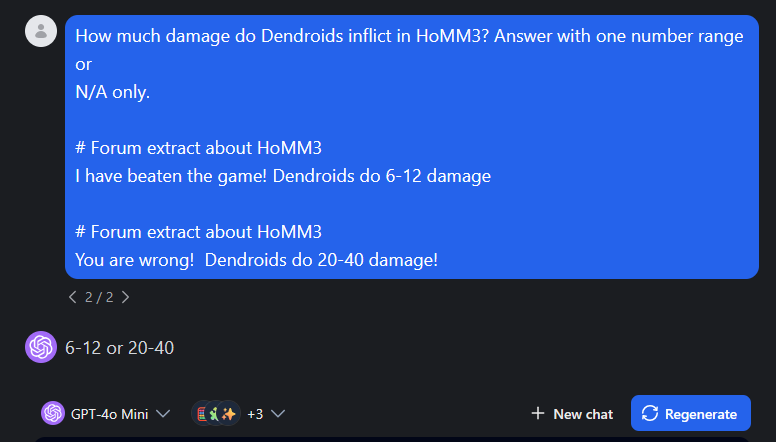
Undefined behavior due to contradictory sources
In presence of several information sources with potential answers chatbots can rely on one or the other unpredictably, or disobey the output format.
Embeddings only return vectors. The vector is the same for the same input, same model, and the same API endpoint.
But we have seen differences between the OpenAI endpoint and the Azure endpoint for the same model. So a pick an endpoint and stick with it to avoid any differences. There could be very slight roundoff errors in the embedding when calling it over and over for the same (above) configuration, but this is in the noise and won’t effect your search result.
As per the quote, not only the input must be the same and the same model release, but also the API endpoint. Calling the same embedding model (like text-embeddings-3-large) an Azure endpoint and OpenAI endpoint might yield different results. But even then, there might be some rounding differences in returned embeddings. This doesn’t sound like a big issue because it should not affect the overall performance later in the pipeline, But for the developers, writing unit tests this can cause some headache if they, for instance, compute SHA values of embeddings.
Code
client = OpenAI()text = f"The Tesla company achieved a record production of 1.5 million vehicles in 2023, reflecting a growth rate of 20% compared to 2022."def compute_fingerprint(embedding): hash_obj = hashlib.sha256() hash_obj.update(np.array(embedding)) return hash_obj.hexdigest()embeddings = []for i in range(5): embedding = client.embeddings.create(input=[text], model="text-embedding-3-large").data[0].embedding embeddings.append(embedding)for e in embeddings: print(compute_fingerprint(e))
cosine similarity search works non-intuitively for us, and may fail unexpectedly in cases where simple string match search would not. In the example below, cosine similarity of a text vs a small, but exact chunk of it returns values below widely used threshold. For that reason, number one rule for information retrieval systems is to use hybrid search.
Code
text = f"The Tesla company achieved a record production of 1.5 million vehicles in 2023, reflecting a growth rate of 20% compared to 2022. All revenue streams reported growth, except for the Autonomous Driving, which still is in the development phase."areas = "Autonomous Driving, Electric Vehicles, Renewable Energy, Autonomous Driving, Battery Technology, Automotive Industry"def cosine_similarity(a, b) -> np.double: return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))def compute_embeddings(texts): result = client.embeddings.create(input =texts, model="text-embedding-3-large") return [d.embedding for d in result.data]for area in areas.split(", "): txt = text.replace("Autonomous Driving", area) print(f'...{txt[110:220]}...') print(area) a, b = compute_embeddings([area, txt]) distance = cosine_similarity(a, b) result = 'FOUND' if distance > 0.6 else 'NOT FOUND' print(f"distance:{distance:0.2f}. {result}") print("--------------------------------")
Output
...% compared to 2022. All revenue streams reported growth, except for the Autonomous Driving, which still is in ...VSAutonomous Drivingdistance:0.35. NOT FOUND--------------------------------...% compared to 2022. All revenue streams reported growth, except for the Electric Vehicles, which still is in t...VSElectric Vehiclesdistance:0.41. NOT FOUND--------------------------------...% compared to 2022. All revenue streams reported growth, except for the Renewable Energy, which still is in th...VSRenewable Energydistance:0.31. NOT FOUND--------------------------------...% compared to 2022. All revenue streams reported growth, except for the Autonomous Driving, which still is in ...VSAutonomous Drivingdistance:0.35. NOT FOUND--------------------------------...% compared to 2022. All revenue streams reported growth, except for the Battery Technology, which still is in ...VSBattery Technologydistance:0.36. NOT FOUND--------------------------------...% compared to 2022. All revenue streams reported growth, except for the Automotive Industry, which still is in...VSAutomotive Industrydistance:0.43. NOT FOUND--------------------------------
Tokenization
Common issues due to tokenization
due to tokenization LLM has issues with many simple tasks (spelling, simple string processing) or has problems when encountering strings like < |endofstring| >, etc. many of the issues were patched in advanced models or using tools and agents in combination with LLM
spelling words, spelling tasks like reversing strings: some tokens denote multiple quite long character sequences, so too much is cramped into one token
asking the model to split a string into a list of characters first and then answer your question helps
LLM are worse at handling non-English language, not only because the model itself has seen less data, but also because the tokenizer was trained on less data from other languages, so its compression is worse
GPT4 has seen major improvements in Python coding vs GPT2 partially due to the way their new tokenizer handled repeated spaces and indentation
handling of special tokens by chance encountered in the input: < |endofstring| >
trailing whitespace issue: the model is really confused, because it has never or rarely seen whitespace without anything after that, same is true for incomplete special tokens like .DefaultCellSty instead of the .DefaultCellStyle.
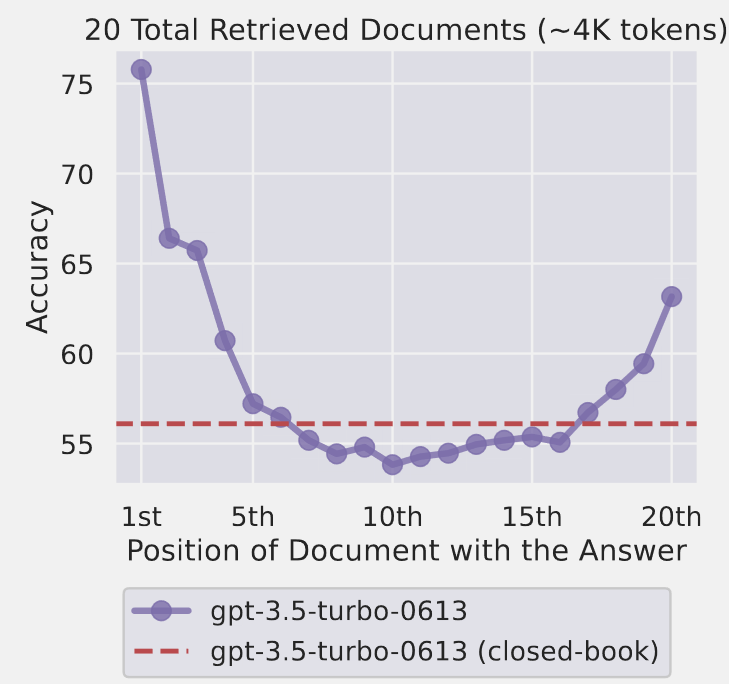
The effect appearing within long context for LLM, when retrieving relevant info from the context is more successful, when it is stored in the beginning or in the end of the context.
Figure 1: Changing the location of relevant information (in this case, the position of the passage that answers an input question)
within the language model’s input context results in a U shaped performance curve —
models are better at using relevant information that occurs at the very beginning (primacy bias) or end of its input context (recency bias),
and performance degrades significantly when models must access and use information located in the middle of its input context.
Often databases may contain information in multiple languages, other than the user query. Not to miss out on relevant chunks of context, use query expansionpattern
Resources
Links to this File
table file.inlinks, file.outlinks from [[]] and !outgoing([[]]) AND -"Changelog"